Stable-Diffusion 通过骨架分析插件ControlNet 来制作超有意境的图片
准备环境
开始前的准备工作
安装 Python 3.10.6
安装 git
安装 cuda
正式开始安装的步骤:
1.安装cuda
查看显卡驱动和CUDA版本
打开nvidia控制面板,点击左下角的系统信息
然后点击组件,查看cuda版本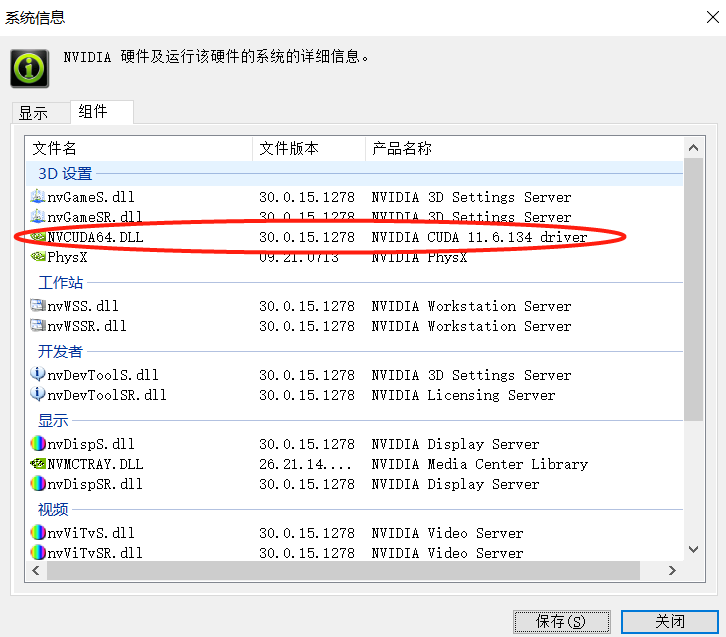
看到我这里是11.6.134
显卡驱动和CUDA之间的版本对应关系
官网地址:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
cuda下载
cuda下载地址
找到自己合适的版本后,点击进去,选择exe本地文件下载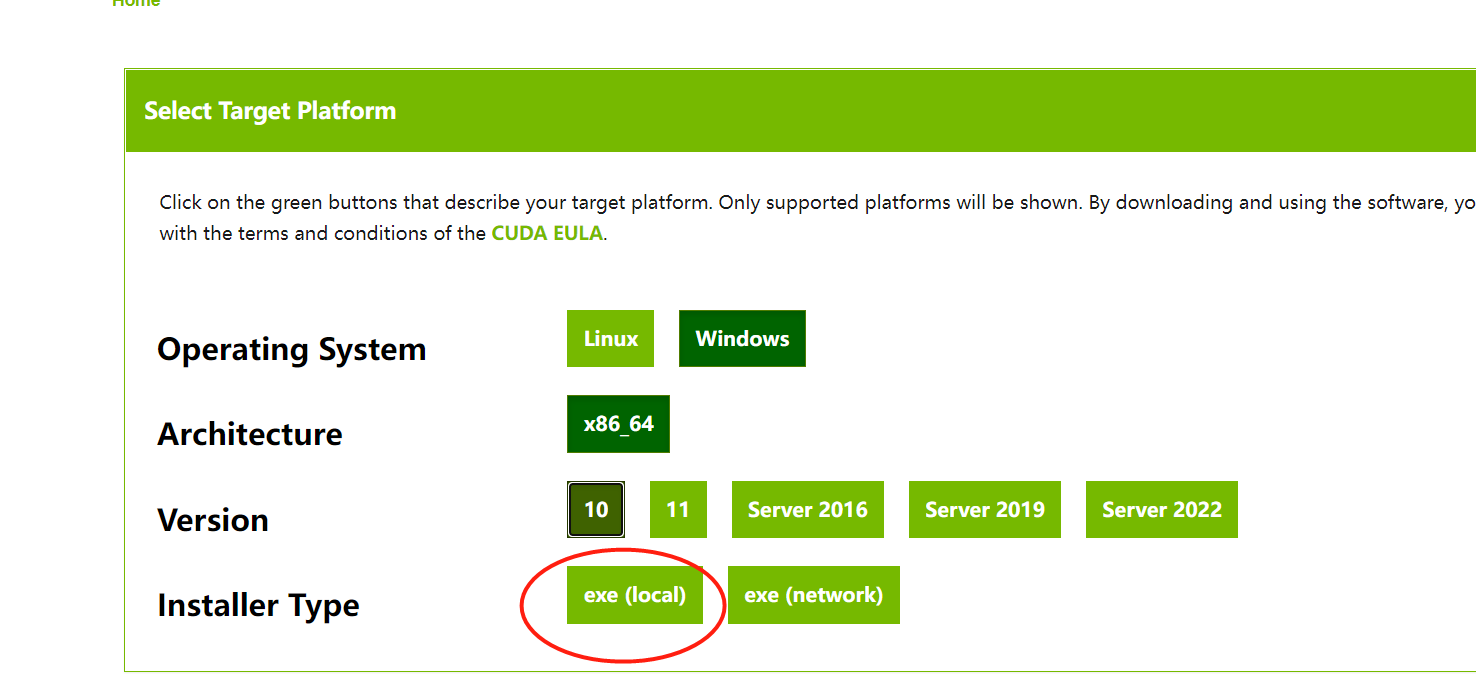
注意这里选择的版本不对应,可能会安装失败。
cuda安装
下载完后,选择自定义安装。
把选择visual studio,取消这个复选框,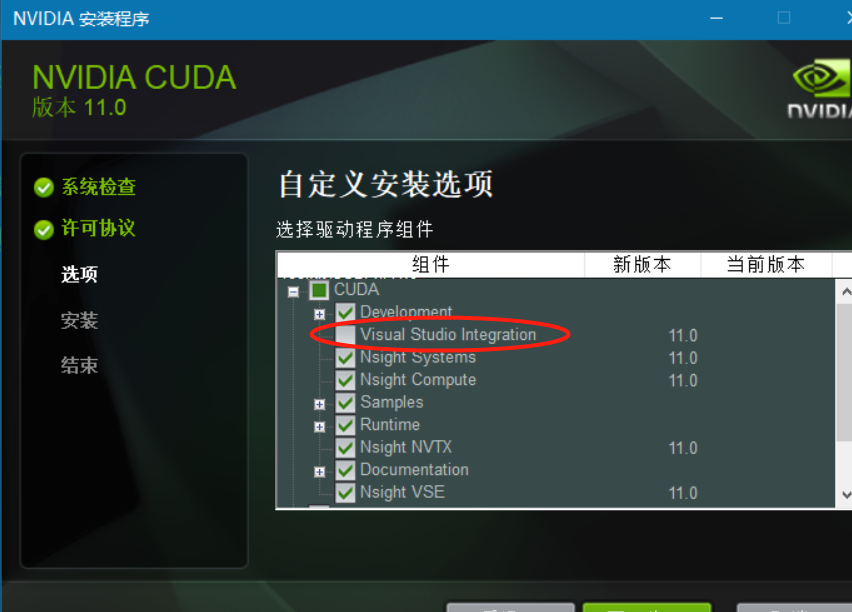
剩下的一直下一步就好了。
1.下载 Stable-Diffusion-webui
Github开源项目,中文语言包 (注意:大陆用户请挂梯子,否则打不开)
安装前先下载torch和torchvision
torch下载
选择对应版本下载,我这里选择的torch-1.13.1+cu117-cp310-cp310-win_amd64.whl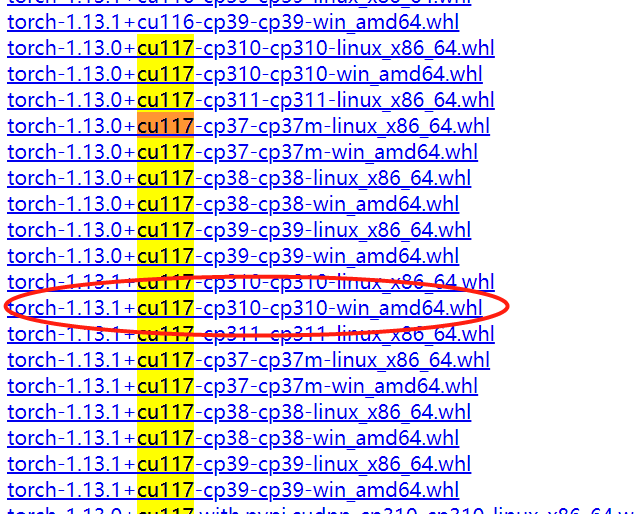
torchvision下载
选择对应版本下载,我这里选择的torchvision-0.14.1+cu117-cp310-cp310-win_amd64.whl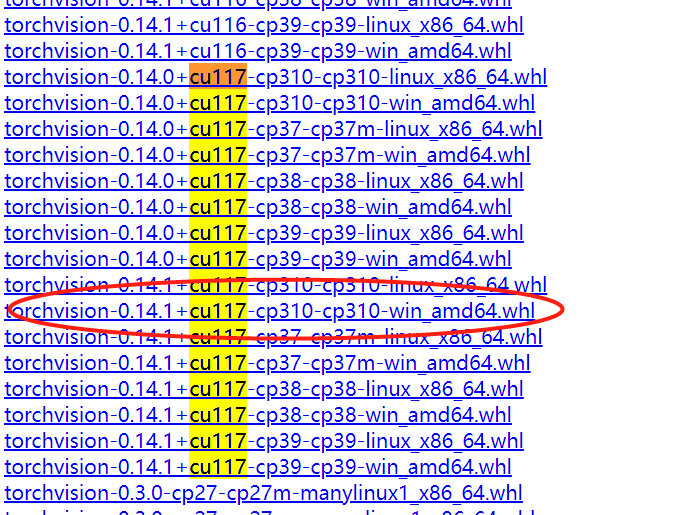
安装Stable-Diffusion-webui
手动安装Stable-Diffusion-webui环境
解压Stable-Diffusion-webui,先运行下webui.bat,运行下就关闭,省的卡死。
运行的原因是:自动生成一个虚拟环境venv,并创建了venv目录。
升级下pip安装目录
1 | 你解压的目录\stable-diffusion-webui\venv\Scripts\python.exe -m pip install --upgrade pip |
安装torch,运行命令如下
1 | 你解压的目录\stable-diffusion-webui\venv\Scripts\python.exe -m pip install 你下载的目录\torch-1.13.1+cu117-cp310-cp310-win_amd64.whl |
安装torchvision,运行命令如下
1 | 你解压的目录\stable-diffusion-webui\venv\Scripts\python.exe -m pip install 你下载的目录\torchvision-0.14.1+cu117-cp310-cp310-win_amd64.whl |
安装stable-diffusion-webui所需的其他环境模块,requirements安装命令如下:
1 | 你解压的目录\stable-diffusion-webui\venv\Scripts\python.exe -m pip install -i https://pypi.doubanio.com/simple/ -r requirements.txt |
安装一下其他模块,要不也会报错。命令如下:
1 | 你解压的目录\stable-diffusion-webui\venv\Scripts\python.exe -m pip install open_clip_torch xformers gdown |
更改Stable-Diffusion-webui的配置环境
1.打开webui.bat文件,修改
–num_cpu_threads_per_process=1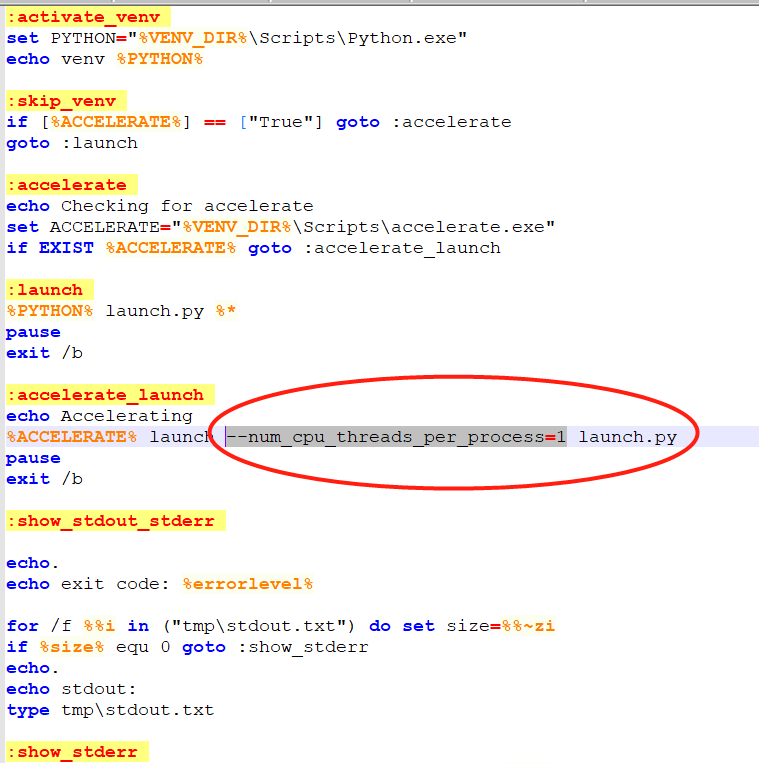
2.打开webui-user.bat文件,修改
添加
1 | set PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:24 |
修改
1 | COMMANDLINE_ARGS=--ckpt .\models\Stable-diffusion\novel-ai.ckpt --medvram --autolaunch |
4G 显存的增加 –medvram ,即上面配置。
2G 显存的增加 –lowvram ,即上面–medvram换成–lowvram,再输入空格然后把下面这段加上
1 | COMMANDLINE_ARGS=--ckpt .\models\Stable-diffusion\novel-ai.ckpt --lowvram --autolaunch --always-batch-cond-uncond --precision full --no-half --opt-split-attention-v1 --use-cpu sd |

运行Stable-Diffusion-webui
运行webui-user.bat即可。
本项目至少需要4GB的GPU内存和5GB的可用系统内存
成功后,访问http://127.0.0.1:7860/这个地址
安装中文语言包
点击扩展插件,点击从网址安装,输入地址中文语言包 ,然后点击安装,安装完成后,点击已安装,点击应用并重启用户界面即可
2.安装扩展
点击扩展插件,点击从网址安装,输入地址:扩展地址,然后点击安装,
安装完成后,点击已安装,点击应用并重启用户界面即可
3.下载ControlNet模型链接选择里面的 control_sd15_openpose.pth,
下载后放入./stable-diffusion-webui/extensions/sd-webui-controlnet/models 文件夹下
4.重启后,进入 WebUi 选择 ControlNet模型
5.载入训练好的模型:stablydiffuseds_26
也就是模型:StablyDiffused’s Aesthetic Mix 点击下载
6.载入图片进行骨架分析,并输入下面的正负关键词:
正面关键词:
1 | 4 girls,4 girls on the beach,back to the sea,White dress,beautiful white gauze skirt,bikini,intricate,elegant,highly detailed,digita painting,concept art,summer lights,queen,sunset,orange sky,pink nightgown,simple background,soft light<lora:dalcefopainting_Lora300:1> |
负关键词:
1 | nude,naked,hands,cartoon,thick strokes,((disfigured)),((bad art)),((deformed)),((poorly drawn)),((extra limbs)),((close up)),((b&w)),weird colors,blurry,complex |
关键词大家可以根据自己的需要进行修改,最后生成即可
更多ai模型请查看《常见ai模型汇总》

